手写静态博客生成器
AI 摘要从零写一个静态博客生成器是怎么一步步想清楚的?以 MD-Render(Vector)为例,用最朴素的语言讲清楚它每一块为什么这样设计、踩过哪些坑、最后为什么又换回了一个 400 行的小脚本。
先说清楚:什么是"静态博客生成器"
想象你在电脑上写了一篇 Markdown 文章。Markdown 是那种用 # 表示标题、用 ** 表示加粗的纯文本格式,写起来很爽,但浏览器不认识它——浏览器只认识 HTML。
所以,要让全世界都能在浏览器里看到你写的东西,就得有一个程序帮你把 .md 变成 .html。这个"程序"就是博客生成器。
"静态"两个字的意思是:生成出来的东西是一堆普普通通的 HTML 和 JSON 文件,不需要后端数据库、不需要服务器实时计算。把它们上传到 CDN(简单说就是一个遍布全球的文件仓库),用户打开你的网站就是直接下载文件,速度非常快、成本也非常低。
市面上这样的生成器有很多,Hexo、VuePress、Hugo 都是。每一个都很成熟、文档齐全、功能繁多。那为什么还要自己写呢?
我为什么不用现成的
现成工具最大的限制在于:它们把"解析 Markdown"和"渲染成网页"捆在一起了。
举个例子。Hexo 的流程大致是这样的:读你的文章 → 解析成一个 JavaScript 对象 → 把这个对象塞进 EJS 模板里 → 输出成 HTML。这里 EJS 模板决定了最终页面长什么样。换句话说,你如果想用 React 或 Vue 来写前端页面?对不起,Hexo 不支持,你得另外写 React 主题,然后绑死在 Hexo 的那个对象格式上。
我想要的是另一种形态:解析器只管把 Markdown 变成 JSON 数据,至于怎么渲染成页面,交给前端框架自己决定。这样我今天用 Vue 写主题,明天想换 React 也随意,反正底层的数据是一样的。
这个想法落成了 MD-Render(内部代号 Vector),从 2023-02 开工,到 2023-03 写了个能跑的 MVP 版本就停下来了。下面就慢慢讲它是怎么长出来的。
最小可行版本:从 Markdown 到 JSON
抛开所有花哨的东西,这件事的本质就是一个函数:输入一个 Markdown 文件的路径,输出一个 JSON 对象。
真正要写的时候,你会发现这一步其实很简单,因为已经有现成的库帮你做掉了大头:
front-matter:Markdown 文件开头如果有一段用---包起来的 YAML,它能帮你把里面的信息(标题、时间、标签之类)抠出来markdown-it:负责把 Markdown 正文转成 HTML
所以单文件转换的代码其实就是这几行:
const rawContent = fs.readFileSync(filePath, "utf8");
const { attributes, body } = fm(rawContent);
const html = md.render(rawContent);
return {
title: attributes.title,
content: html,
word: body.length,
// ...
};写到这里就已经能用了。但一个博客不可能只有一篇文章,我们得处理成百上千个文件,还要生成目录、处理图片、支持插件扩展……于是问题一个个冒出来。
问题一:怎么同时处理很多个文件?
最直观的写法是用一个 for 循环,一个一个处理:
for (const file of markdownFiles) {
await renderMarkdownFile(file);
}这样写代码没错,但有一个很明显的浪费——每次 await 都要等当前文件完全处理完才开始下一个。而电脑读文件的速度远远跟不上 CPU 的速度,大部分时间 CPU 其实是在空等。
更好的办法是"一起发起、一起等待":
const jobs = markdownFiles.map(renderMarkdownFile);
const results = await Promise.all(jobs);.map 会把所有文件同时开始处理,Promise.all 负责等它们全部完成。你可以把它想成餐厅里上菜——与其让厨师做完一盘才开始下一盘,不如把所有订单一起下、谁先好谁先端上来。这就是 engine/setup.ts 的核心思路:
export async function setup() {
await initEngineRuntime();
const config = getRuntime().getConfig();
const markdownFiles = await getMarkdownFiles(config.dataDir);
const jobs = markdownFiles.map(renderMarkdownFile);
const hookObj = await Promise.all(jobs);
executeHooks(hookObj);
}问题二:同一个文件不要读两次
博客生成器在运行过程中,常常会多次用到同一个文件的内容。比如某一步想算文件 md5(一种"指纹",用来判断文件有没有变),另一步想读正文的长度,再一步想解析 front-matter——如果每一步都从硬盘重新读一遍,就又在做无用功。
解决办法是用一种叫 "memoize(记忆化)" 的套路。lodash 提供了一个现成的 memoize 函数,传同样参数给它,它会直接返回上一次的结果,不再执行原函数:
export const getFileReader = memoize(
(filePath: string) => new FileReader(filePath)
);这样不管谁、在哪里调 getFileReader("/path/to/a.md"),拿到的都是同一个对象。这个对象里存着文件内容、md5、时间戳——都是一次性算好、后续白嫖。
FileReader 本身还有一个小巧思:构造的时候它什么都不做,只有第一次调 .ready() 才真正去读硬盘。这样即使某个文件后来被过滤掉了(比如文章标成了 draft: true),也不会白白读一次。这种"用到才算"的做法叫惰性求值。
问题三:IO 别卡住主流程
上面那几行只是渲染,接下来要做"图片搬家"这样的活——文章里用到的图片,得从原位置拷贝或者下载到产物目录。图片动辄几百 KB、远程下载可能几秒,这些操作都很慢,让主流程一个个等显然很傻。
于是有了一个小小的"调度器",utils/schedule.ts 里就十几行代码:
export class Scheduler {
private tasks: Array<Promise<any>> = [];
public async addAsyncTask(asyncTask: () => Promise<any>) {
this.tasks.push(asyncTask());
}
public async waitForAllTasks(): Promise<any[]> {
return Promise.all(this.tasks);
}
}你把它想成一个"待办事项本"。每遇到一张图,就往本子上记一笔"这张图等会儿搬",然后立刻回主流程继续干别的活;等所有文章都处理完了,再回来看本子上剩下哪些图没搬完,统一等一下就行。
注意一个细节:addAsyncTask 里 asyncTask() 是立刻被调用了的。也就是说,往本子上记的不是"待办",而是"已经在跑的任务的句柄"——任务本身已经在后台并发地跑,我们只是把引用存起来方便后面统一收尾。
问题四:把"固定流程"变成"插件式"
写到这里你会意识到:文章渲染完之后,还得做一堆加工。比如:
- 根据正文第一张图自动生成封面
- 扫一遍标题,生成目录(TOC)
- 过滤掉标了
except: true的草稿 - 把所有文章按目录分组,生成列表页的数据
这些步骤要不要写死在主流程里?可以,但太死板了——以后我想加一条"统计每篇文章的字数分布"的步骤,就得去改核心代码。更灵活的做法是 hook(钩子)。
你可以把 hook 理解成"一连串检查点"。主流程跑到某个检查点,会依次调用所有注册在这个检查点上的函数,每个函数都能拿到当前的数据、修改它、再传给下一个。新功能就是在这些检查点上加一个新函数,完全不动主流程。
Vector 定义了两个检查点:
init:数据刚出炉,做各种加工beforeSave:要写到硬盘前,做组织排版
内置的 init 钩子有三个:
// 1. 扔掉草稿文章
function filterExcept(hookObjs) { ... }
// 2. 没封面的,就用正文第一张图当封面
function generateCover(hookObjs) {
hookObjs.forEach((obj) => {
const res = obj.content.match(/<img src="(.*?)"(.*?)>/);
if (res) obj.cover = res[1];
});
}
// 3. 扫正文里的 <h1>~<h6>,生成目录
function generatePostToc(hookObjs) {
const reg = /<(h[1-6])>(.*?)<\/\1>/g;
// ...
}内置的 beforeSave 钩子有两个,一个按目录聚合生成 index.json(后面会讲这是干嘛的),一个真正把 JSON 写到硬盘。
用户想加自定义逻辑,调 registInitHook 往列表里塞一个函数就行。所有钩子最后被拼成一条长链,一个个顺序调用:
const bundleHooks = [
...hooks.init, ...initHooks,
...hooks.beforeSave, ...beforeSaveHooks,
];
for (const hook of bundleHooks) {
const res = hook(data);
data = res instanceof Promise ? await res : res;
}这种"主流程只管串检查点、具体活儿交给钩子"的思路,在前端工具里遍地都是:Webpack、Babel、Rollup、Vite 骨子里都是这种结构。
图片怎么搬?
先说一个关键决定:图片搬家的逻辑只处理 front-matter 里写的图片,而不是正文 Markdown 里的。
为什么?正文里的图片 markdown-it 会帮我们渲染成 <img> 标签,那些我们其实不用管(前端自己处理就行);但 front-matter 里的图片——比如 cover: ./a.png——是 YAML 里的一个字段,markdown-it 是不看它的。这个必须我们自己处理。
处理方法就是递归遍历 YAML 对象树,见到字符串、且后缀是 .jpg .png .gif 这种,就当成图片来处理:
function processObject(filePath: string, obj: any) {
for (const key in obj) {
let objValue = obj[key];
if (typeof objValue === "string") {
if (!isImageURI(objValue)) continue;
if (!isHttpURI(objValue)) {
objValue = path.resolve(path.dirname(filePath), objValue);
}
const handler = isHttpURI(objValue) ? urlImageHandler : localImageHandler;
obj[key] = handler(objValue);
} else if (typeof obj[key] === "object") {
processObject(filePath, obj[key]);
}
}
}两种情况分别交给两个 handler:
export function localImageHandler(imagePath: string) {
const destinationPath = getImageSavePath(imagePath);
imageSchedule.addAsyncTask(async () => {
await ensureDirExists(path.dirname(destinationPath));
await fs.promises.copyFile(imagePath, destinationPath);
});
return getImageRenderUrl(imagePath);
}注意 handler 不是马上去搬图——它只是往上面讲的 imageSchedule 扔一个"搬图任务",然后立刻返回"这张图以后会在哪里"的 URL。主流程拿到这个 URL 就可以继续往下走,完全不用等。搬图的活儿在后台悄悄做。
这种"先许诺、后兑现"的拆分方式,是整个生成器里反复出现的套路。
目录是怎么变成链接的
再说 index.json。它的意义其实很简单:你的 data/ 目录下可能是这样的:
data/
tech/
article-1.md
article-2.md
life/
diary-1.md对应生成出来的产物就是:
dist/
tech/
index.json ← 列表页数据:[{id:..., title:...}, ...]
<id1>.json ← 详情页数据
<id2>.json
life/
index.json
<id3>.json前端打开 /tech 路由时,去拉 /tech/index.json 就能渲染出文章列表;点进一篇文章,再去拉对应的 <id>.json 渲染详情。
这样设计的好处是:整个博客的"路由"就是你文件夹的形状。你没必要维护路由表,加一篇文章就是往目录里扔一个 .md 文件,再跑一遍生成器,对应的 JSON 就出来了。这种"文件系统即路由"的风格,Next.js、Nuxt 这些主流框架后来都采用了。
配置文件的小 trick:eval
Vector 允许你写一个 vector.config.js 文件做配置(比如改产物目录、接入主题)。加载这个文件的代码长这样:
const data = await fs.readFile(path.resolve(rootDir, "vector.config.js"));
const obj = eval(data.toString());
Object.assign(userConfig, obj);eval 大家可能听过但一直被提醒"别用",因为它能执行任意字符串代码,有安全隐患。但在这里它正好解决了一个头疼问题:Node.js 同时存在两种模块规范(CommonJS 和 ESM),用 import() 或者 require() 读取配置文件会牵扯一堆兼容性麻烦。eval 就一行搞定。
这跟我上一篇讲 ES6 翻译器里用 eval 把源码当"免费 parser" 是同一个思路:让 JS 运行时替我做解析的活。代价是"能执行任意代码"——但配置文件本来就是自己写的,这个代价在这个场景下可以接受。
性能优化之一:搜索怎么做才快
开源仓库里搜索模块还是空的,但当时内部版本是这么做的:前端页面加载完成之后,偷偷在后台拉一份所有文章的全文数据。等你真的点开搜索框,数据已经躺在内存里了,搜索本身只是一个"找字符串 + 套高亮"的活,几乎瞬间完成。
但这里马上有一个问题:每写一篇新文章,这份"全文数据"就得重新算一次——博客一大这就慢了。
这时候有一个挺经典的思路可以用:局部性原理。意思是一个文件如果最近被改过,那它接下来很可能还会被继续改(还在写草稿嘛)。于是可以把最近几分钟内改过的文章标记成 "hot",暂时不把它们算进全文数据里,等它们稳定下来再合并一次。实测下来这个优化大概能省 10% 的构建时间。
本质上是"用延迟合并换掉每次全量重算"。这种思路其实就是前端框架里 Vue 做脏检查、React 做 reconciler 的一种简化版。
性能优化之二:md5 才是瓶颈
更进一步 profile 一下会发现,整个生成流程里最慢的一步居然是算 md5——因为图片文件很大,一张大图用 Node 的 crypto.createHash 算一次要 10 几毫秒,几十张图加起来就是秒级。

md5 是一种哈希算法,输入任意长度的数据,输出一个 32 位的"指纹"。Vector 用它来:
- 给文章生成稳定的 id(内容没变 → 指纹没变 → id 稳定)
- 判断图片是不是被改过(指纹变了才需要重新上传)
对 md5 这一步,Vector 做了两层优化:
第一层是在 JavaScript 层面套 memoize,同一段内容只算一次。这在开源代码里能看到:
export const getStringMD5 = memoize(function (input) {
const hash = createHash("md5");
hash.update(input);
return hash.digest("hex");
});第二层是针对大文件和图片,用 N-API 接一个 C++ 实现。C++ 版本的 md5 能利用 CPU 的向量指令(SIMD),比 JavaScript 快一个数量级。这部分代码没推进到公开仓库。
这里其实有一个值得记住的经验:IO 密集型 + 哈希密集型的流水线里,真正值得优化的是"哪些可以缓存" + "哪些可以交给更快的实现",而不是扣代码层面的 if-else。
性能优化之三:把小文件塞进内存
还有一条很土但很有效的优化。我们这套生成器会反复读一些小文件(比如主题模板、配置、各种中间数据),这些文件加起来也就几兆。与其每次都去硬盘读,不如在程序刚启动时一次性把它们全部读进内存里当缓存:
async function readFile(url) {
const content = getFileContent(url);
if (content === undefined) {
return fs.readFile(url);
}
return content;
}Node.js 程序默认堆内存上限是 4GB(老版本),装几百个小文件零压力。代价是启动时多一点点预热开销,换来后续"读文件"这个动作对 CPU 的等待接近为零。
最后看看战绩
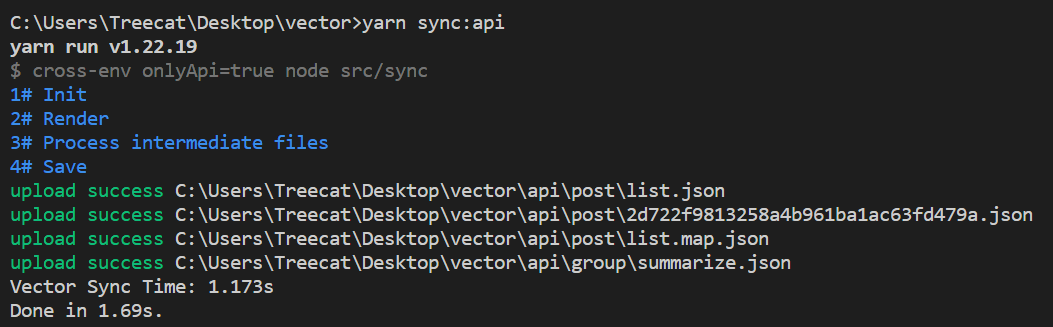
这些优化加起来,最终效果如何?我的博客在 i7-9750H 加 100M 带宽的环境下,全量同步一次大概 1.173 秒:
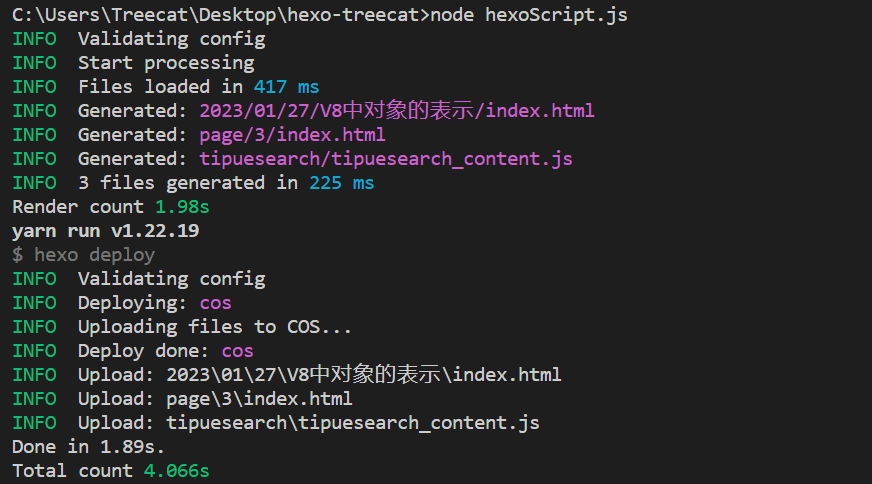
作为对照,我用 Hexo 跑同样内容,就算是只有一页的官方默认主题也要 4.066 秒;换了第三方主题常常十几秒起步。
这倒不是在 diss Hexo——Hexo 是面向所有人的通用框架,得兼顾插件生态、历史兼容、各种主题;而 Vector 从第一天就是"只给我自己用",能砍的通用性全砍掉了。
两者对比不公平,但它说明一件事:当你不需要通用性时,可以砍掉的东西远比想象的多。
一些做得不够好、值得坦白的地方
写到这你可能觉得这工具挺完整。其实它有一堆小问题,趁复盘一起说了。
"双重校验锁"这个注释是错的。 代码里有一段:
} catch (err) {
if (err.code === "ENOENT") {
// 双重校验锁
if (dirCache.has(filePath)) return;
await fs.mkdir(filePath, { recursive: true });
dirCache.add(filePath);
}
}"双重校验锁" 这个词源自 Java 多线程编程,用来防止竞态条件。但 JavaScript 是单线程的,根本就不存在这种竞态——这里真正在工作的其实是两点:一是 fs.mkdir(..., { recursive: true }) 本身就是幂等的(目录已经存在不会报错),二是 dirCache 能让重复调用短路返回。我当时注释里乱用了一个听起来很酷的术语,属于想装懂的错误示范。
saveObj 这里往 Scheduler 扔了任务,但从没调过 waitForAllTasks。 主流程跑完就当完事,剩下的写盘操作靠 Node 进程退出前自动把 pending 的 Promise 执行完来兜底。这个能跑但不干净——依赖了一个 implicit 的行为,出事很难排查。正规做法应该显式地 await 所有任务。
image.cache.ts 是个空壳。 想给远程图片加指纹缓存避免重复下载,接口留了一行 return [false, ""],核心逻辑一直没填。
sync.cos.ts 是个空函数。 原计划支持直接同步到腾讯云 COS 的,也留了一个空的 async function async2Cos() {}。
这些地方如果 Vector 一直在长期维护,早就该回填;但它停在 MVP 状态之后,这些 TODO 就再也没动过。
为什么最后没继续?
Vector 从 2023-02-17 开始,到 2023-03-23 写完最后一个 commit,就放下了。原因不是技术走不通,而是我慢慢意识到——我根本不需要这么重的东西。
这个博客现在实际用的是什么?是仓库里另一个脚本 web/scripts/build.mjs:直接把 data/ 下的 Markdown 过一遍 markdown-it,套一个 HTML 模板,写到 web/dist/。整个文件 400 行左右,没有 hook、没有 Scheduler、没有 memoize,跑完几十篇文章不到一秒。
Vector 的那套插件化架构、两段式 hook、调度器、md5 的 C++ 改造——在一个有几十个贡献者、每天都在加需求的公共博客引擎里会非常值钱。但对于"只给我自己用、一年更新十几篇文章"这个场景,它就是过度设计。
所以 Vector 从某种意义上是个实验品:它让我把这一类工具怎么设计想清楚了、证明我能做出来、攒够了可迁移的经验,然后心甘情愿地退回到一个 400 行的脚本——知道自己不需要什么,也是一种收获。
如果你是新手,从这篇文章里能带走什么
一篇讲具体工具的文章,底下其实藏着几条通用的道理,列在这里做个小结。
第一,"流水线"是软件工程里最常见的形状之一。 编译器、打包器、博客生成器、ETL 数据处理,骨子里都是"读 → 解析 → 加工 → 写出"这条四步走。下次你遇到类似任务,先画出这条流水线,再想怎么拆。
第二,两种最基础的性能小工具要记住:记忆化(memoize)和调度器(Scheduler)。 前者解决"别重复算",后者解决"IO 慢别卡住"。这两招用好了,能覆盖 80% 的日常性能问题。
第三,想让工具可扩展,就用 hook(钩子)。 主流程只管串起检查点,每个检查点上随便挂函数。这种模式比"在主流程里写 if-else"干净一百倍,前端几乎所有工具链都用的是这个。
第四,也是最重要的:别一开始就写"大而全"的工具。 先写能跑的最小版本,跑一段时间看看真实需求是什么,再决定要不要加抽象。Vector 教我的最重要一课是——当你意识到自己不需要时,能心安理得退回去,比做一个"看起来很厉害"的东西重要得多。
工具的寿命决定工程的强度。 这句话也写在上一篇文章的结尾,算是这两次复盘共同的收束。